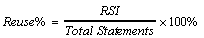
Jeffrey S. Poulin, Lockheed Martin Federal Systems
Software reuse has become a widely accepted way
to reduce costs, shorten cycle times and improve quality. Unfortunately,
very few OO programs have a method to actually quantify and realistically
estimate the results that they have achieved. To do this, the
program must have objective, easy-to-acquire, and easy-to-understand
metrics. This article outlines a simple and effective set of metrics
that apply to projects using OO tools and techniques.
Object-orientation brings many opportunities for
clarifying design, modeling real-world problems, and reducing
the costs of maintenance. The concepts and language features
of OO also make it easier to reuse objects in more than one application.
This ability to design and implement software for use in many
places has attracted the attention of nearly everyone involved
in large-scale software development. Not surprisingly, OO practitioners
cite reuse as one of the principle advantages of object-orientation.
Most people involved in software development intuitively
agree that reuse has many benefits. These include lower development
costs, faster cycle times, and better software quality. Consequently,
we see that software developers derive a good part of their motivation
to reuse from an expectation of financial reward. This motivation
often kindles excitement and the first attempts at a formal reuse
program.
For reuse to occur, however, someone has to organize,
plan for, and develop the assets, software, and people for others
to reuse. This requires an investment, and quite frankly more
than just a little foresight. Business decisions drive reuse!
Can we justify the investment with business case? Even though
most people might intuitively believe that reuse will eventually
yield financial advantages, few have enough conviction to risk
their current budget for the benefit of others.
"Business decisions drive reuse!"
Because OO facilitates reuse, reuse metrics can help
build a decisive business case for OO investments. Using simple
models and basic assumptions, reuse metrics make an exceptional
technology insertion tool. We have developed a pragmatic approach
to OO reuse metrics and use the metrics in many organizations
as part of very successful reuse programs.
This article discusses some of the practical issues surrounding measuring OO reuse. It then presents a practical set of reuse metrics for estimating the financial benefit of reuse on a project. The results clearly show the substantial rewards of reuse and can help build a reuse business case for any organization.
Many discussions have appeared on methods for selecting
or recommending object-oriented reuse metrics [for example, Vaishnavi96].
However, before we can select metrics, we have to have a consistent
and reliable means for classifying and collecting data to go into
the metrics. Unfortunately, this process involves many pernicious,
subtle, and very important issues [Poulin97a].
These issues persist throughout most published reuse
metric models. These models use a simple cost-benefit (C-B) method,
which in all instances consist of the same basic idea: take the
sum of the costs and the sum of the benefits and make a reuse
investment decision depending on whether the good exceeds the
evil. However, none of these methods give any guidance or advice
on how to estimate, much less quantitatively derive, the costs
and benefits of reuse. Even more importantly, none of the methods
define the data that we need to collect; in other words, what
counts and does not count as reuse. With critical input left
to chance or intuition, we cannot fail to wonder how these methods
could provide reliable or useful information.
During OO development, finding good objects and abstractions
depends on a combination of disciplined methods and insight from
the designer. We recognize good designs because they exhibit
attributes such as flexibility, modularity, and a certain reflection
of the real world in a model that elegantly maps to the object-oriented
paradigm. Good designs do not guarantee reuse in OO development
any more than they do in procedural development. Imaginative,
perceptive developers will use subclassing, inheritance, and polymorphism
to abstract the common elements of the systems they build and
to minimize the number of classes and methods that they must write
and maintain.
The rationale for defining reuse does not
depend on language features but rather on whether someone saved
effort by using software that they obtained from "someplace
else." Typically, "someplace else" refers to another
software development team or another software program. We call
this criterion the boundary problem. When a development
team uses classes and methods that originated in another organization
or in another program, those classes and methods "cross"
a notional boundary. When this happens, the development team
reuses the software. If the classes and methods originated from
within the development team, they do not cross a boundary. In
other words, if the team inherits from classes that they developed
for their current project, then they did not reuse those classes
but rather simply used the language features at their disposal.
The rationale for defining reuse does not depend on language features but rather on whether someone saved effort by using software that they obtained from 'someplace else.'
OO reuse inherently involves the use of classes and
methods from shared libraries or other sources outside of the
organization that benefits from the use of that software. We
routinely establish a "reuse development team" early
in a project and assign that team the responsibility for designing
and implementing common software. The other application development
teams will use this common software later in the project. The
reuse development team supports the common software for errors,
enhancements, and configuration control; this saves duplication
of effort across the application teams. When the application
teams use the common software, the software crosses the notional
"boundary" and counts as reuse. This becomes especially
important for our metrics program. When in doubt about what to
count, we always return to the fundamental goal of saving effort,
and ask: "Would the organization have had to develop the
software if they had not obtained it from someplace else?"
While we encourage saving effort any way we can,
the software engineering and reuse communities have long promulgated
disciplined procedures for controlling, configuring, and managing
change of software components throughout the software lifecycle.
As many of us have experienced, uncontrolled change quickly leads
to chaos. Even if we manage to get the product to float out the
door, we secretly pray for (1) a chance to go back and fix our
patches in case they suddenly spring a leak, or (2) a short product
life so we can beach the boat before it sinks on its own.
Designing and building a "leak-proof" software
system requires anticipating and planning for change. Reuse involves
the use of unmodified software from "someplace else."
When we change the code, we call it reengineering because
we have adapted the software for a role outside of its original
purpose. In large scale software development, the short term
benefits of reuse versus reengineering depend, in large part,
on the extent of the modifications. Basili et al. found that
even on small class projects, modifying a little code gives almost
the same benefit as unmodified reuse, whereas modifying more than
25% of the code results in the same kinds of errors and quality
as new development [Basili96]. In fact, most evidence shows that
reengineering can actually cost more than new development.
This penalty can occur if we modify as little as 20% of the code
and almost certainly if we modify more than half [e.g., Stutzke96].
However, the long term benefits of reuse versus reengineering
really stand out during maintenance. With a typical software
post-deployment life lasting 4 times the time it took to write
the software in the first place, the benefits of having to make
changes in one place as compared to trying to track down numerous
variants of the same problem become painfully clear. Reuse, therefore,
means planning for change by designing classes that adapt their
behavior without having to adapt their implementation.
Fortunately, we have many good programming and software
engineering tools at our disposal to help control the mess we
might otherwise make (or sometimes make anyway). OO provides
several graceful ways to manage variation; subclassing, inheritance,
and polymorphism. These techniques have direct analogies for
managing variation in the procedural paradigm (e.g., generics,
parameterized functions, variable macros, etc.). Nonetheless,
most of us have seen how the undisciplined use of language features
can create a cascade of problems in any language.
Most of these problems occur through the careless
management of change. Alistair Cockburn gives a very thorough
discussion of the effects that OO language features can have on
a design in terms of the "messiness" of change [Cockburn93].
Modifying source code (reengineering), whether in the method
body or interface, makes for "messy" change because
the modification propagates to all parts of the system that use
that method. Obviously, reengineered code does not count as reuse.
To avoid reengineering, OO designers should isolate changes both
in the abstract model they build to represent the real world and
in the language features they use to implement the model. Simple
subclassing provides one such means for clean, effective, and
safe reuse.
Nearly all software metrics, including those for
OO, use Lines of Code (LOC) for units. LOC have many well-known
disadvantages but persist for just as many reasons. One of the
most convincing of these reasons comes from the wealth of evidence
that LOC serves as an excellent overall indicator of effort across
all software life-cycle phases. Nonetheless, all our reuse metrics
remain independent of units, and do not depend on conceptual decisions
related to LOC. This means that if an organization uses other
units (for example, function points or objects) all the rationale
that we have discussed and the equations we will introduce below
continue to apply.
One of the disadvantages of LOC lies in that we can
only use LOC once we have started implementation. For OO projects,
objects make an appealing unit because we identify candidate
objects much earlier in the life-cycle. However, using objects
for units deserves a word of caution because of the potential
variation in the size of objects. Should we allow for the fact
that the use or reuse of a small object counts the same as the
use or reuse of a large object? Beware that I have seen reuse
levels vary by as much as a factor of 8 depending on whether
we counted reuse by line of code or by object.
If putting a value on a design proves difficult,
measuring more conceptual products such as frameworks, architectures,
and design patterns (abstract descriptions of designs) proves
even more so. Helm reminds us that a large system may only contain
5-10 patterns [Helm95]. Despite their utility and the insights
they provide, quantifying the benefits of such products such as
patterns still only addresses a small portion of system development.
Until we develop dependable and repeatable methods of measuring
work products in all life-cycle phases, we recommend LOC as an
overall indicator of development effort and reuse.
The most widely used and understood way to convey the level of reuse on a project comes through the use of some form of "percent reuse." Because we see it all the time, I call it the de facto industry standard measure of reuse levels. However, a percent reuse value can give very misleading results unless we have a clear definition of what counts as "reused." We have already discussed a few of the many questions that arise during data gathering, such as determining when software comes "from someplace else" (the boundary problem). Our first reuse metric follows the industry standard, but uses a special symbol, Reuse%, to show that the value comes from a clear, well-defined method of counting these Reused Source Instructions (RSI). The equation simply goes:
Because business decisions drive reuse, we need a metric to show the financial benefit of reuse. The vast majority of reuse economic models incorporate some form of cost-benefit (C-B) analysis. For an OO example, see [Hendersen-Sellers93]; many others, along with a practical guide on how and when to use them, appear in [Poulin97a]. The C-B approach has an intuitive appeal because it uses the commonsense axiom that "If it costs less than the benefits, we should do it." However, none of the C-B models in existence today explain the numerous C-B factors that influence software development, reuse, and OO design. Even if we had such a list, we would find gathering and quantifying every individual C-B factor a nearly impossible task.
To solve the problem caused by the inherent incompleteness of C-B methods, we use two abstractions called the Relative Cost of Reuse (RCR) and the Relative Cost of Writing for Reuse (RCWR).
Every organization will have its own values for RCR and RCWR. Even within organizations the values for RCR and RCWR will fluctuate according to environmental factors such as the experience of the reuser, organizational processes, the complexity of the software, etc. However, substantial quantitative evidence shows that we can assign reasonable default values of RCR = 0.2 and RCWR = 1.5 [Poulin 97a]. For OO development, Pant et al. validate at least one of these default values by finding an RCWR=1.55 [Pant96].
We use RCR and RCWR in our reuse economic model to calculate the total Reuse Cost Avoidance (RCA) of reuse and the Additional Development Costs (ADC) incurred by writing reusable software. In essence, the total financial benefit of reuse to a project, Project ROI, consists of the sum of the benefits experienced by each of the n organizations participating in the project minus the costs of building the software for each organization to reuse.
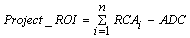
To use this model, we first determine the RCA for each organization. We do this in two steps; because a project benefits from reusing software during the development and the maintenance phases of the life-cycle, we need to estimate both of these factors. During the development phase, we use the value of RCR to estimate the Development Cost Avoidance (DCA). We say that if it took "RCR amount of effort" to locate, evaluate, and integrate a component into our application rather than write it new, we saved an amount of effort proportional to (1-RCR) and the size of the component, in RSI. Specifically:

The Service Cost Avoidance (SCA) accrues in two ways. First, reusable software tends to have up to a 10x better quality than software developed for one-time use [i.e., Matsumoto95]. This means the reuser eliminates a significant maintenance cost. Second, when a reuser experiences a defect, the reuser saves service costs by not having to support the reused software. If we know the historical rate of these errors and the cost to fix them, we can estimate the SCA for a reused component by:
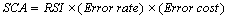
Of course, the total reuse benefit results from the sum of these two avoided costs:
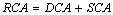
Finally, we need to subtract the additional costs that the project incurred by developing shared software. For this we use the abstraction RCWR. In short, we incur an additional cost proportional to (1-RCWR) and the amount of reusable software that we write. This additional cost equals:
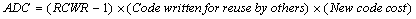
We now put this all together in an example.
Example: Your consulting firm just delivered an application to one of your major clients. In all, three development teams worked to develop the three primary subsystems needed for the application. These teams reused class libraries and methods of 10k LOC, 15k LOC, and 5k LOC, respectively, for a total of 30k RSI. Most of this RSI came from a domain-specific repository of library classes in which your firm has invested. However, during the project your three teams identified and developed 1500 LOC of class libraries that all three teams needed for their subsystems; you expect to add these new classes to your repository.
Because you do not have actual RCR and RCWR data for your teams, you decide to use the default values of RCR = 0.2 and RCWR = 1.5. You call your firm's cost engineers and find out that on projects of this type your developers have a historical error rate of 1.5 errors per thousand LOC and it costs $10,000 to fix these errors after product release. Your cost engineer also advises you to use the industry standard new code development cost of $100/LOC for your calculations.
You calculate the DCA and SCA to find the total RCA:
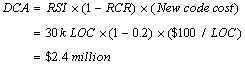

So,
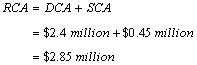
The total benefit of $2.85 million comes from saving 80% of the estimated new development cost and from not having to fix errors in the code you would have written. We now calculate the investment made in producing the 1500 LOC of common classes, and then subtract this investment cost from the RCA to find the Project ROI.
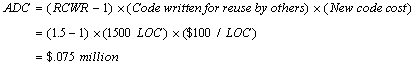
The resulting benefit to the project equals:
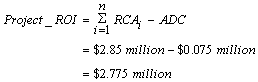
This example shows how to use the abstractions for the relative costs of reuse in simple and effective reuse economic model. The metric estimates the total financial benefit of reuse to your project as almost $3 million [Poulin97b].
Business decisions drive reuse, just as they drive
all other investment decisions. Objective, realistic, and credible
metrics provide the backbone for making these business decisions.
Having a clear definition of what to count lies at the foundation
of all reuse metrics. As a guide, look for where an organization
really saved effort by using classes and methods that it obtained
from "someplace else."
Having a clear definition of what to count lies at the foundation of all reuse metrics.
With the simple, easy-to-understand and easy-to-implement
metrics presented above, we can put together a convincing and
impressive business case for investing in reusable library classes.
We wrote a reuse metric calculator in JavaScript (http://www.owego.com/~poulinj)
to make it easy to play with these assumptions and how they affect
the benefits of reuse. A short time with the calculator shows
that even conservative assumptions yield startling results!
Jeff Poulin (Jeffrey.Poulin@lmco.com)
serves as a Senior Programmer and systems architect with Lockheed
Martin Federal Systems in Owego, NY. Dr. Poulin has over 40 publications,
including a book on reuse metrics and economics recently published
by Addison-Wesley.
[Basili96] Basili, Victor R., Lionel C. Briand,
and Walcelio L. Melo, "How Reuse Influences Productivity
in Object-Oriented Systems," Communications of the ACM,
Vol. 39, No. 10, October 1996, pp. 104-116.
[Cockburn93] Cockburn, Alistair, "The Impact
of Object-Orientation on Application Development," IBM
Systems Journal, Vol. 32, No. 3, 1993, pp. 420-444.
[Helm95] "Patterns in Practice," presentation
at OOPSLA, Austin, TX, 19 October 1995.
[Henderson-Sellers93] Henderson-Sellers, Brian,
"The Economics of Reusing Library Classes," Journal
of Object-Oriented Programming, Vol. 6, No. 4, July-August
1993, pp. 43-50.
[Matsumoto95] Matsumoto, Masao, "Research to
Shed Light on Software Shadows," IEEE Software, Vol.
12, No. 5, September 1995, p. 16.
[Pant96] Pant, Y., B. Henderson Sellers, and J.M.
Verner, "Generalization of Object-Oriented Components for
Reuse: Measurements of Effort and Size Change," Journal
of Object Oriented Programming, Vol. 9, No. 2, May 1996, pp.
19-31, 41.
[Poulin97a] Poulin, Jeffrey S. Measuring Software
Reuse: Principles, Practices, and Economic Models. ISBN 0-201-63413-9,
Addison-Wesley, Reading, MA, 1997.
[Poulin97b] Poulin, Jeffrey S., "The Economics
of Software Product Lines," International Journal of Applied
Software Technology, Vol. 3, No. 1, March 1997, pp. 20-34.
[Stutzke96] Stutzke, Richard D., "Software Estimating
Technology: A Survey," Crosstalk: The Journal of Defense
Software Engineering, Vol. 9, No. 5, May 1996, pp. 17-22.
[Vaishnavi96] Vaishnavi, Vijay K. and Rajendra K.
Bandi, "Measuring Reuse," Object Magazine, Vol.
6, No. 2, April 1996, pp. 53-57.