Adapting Object-Oriented CAD Database Concepts for Computer Aided Software Engineering (CASE)
Jeffrey
S. Poulin and Martin Hardwick
Department
of Computer Science
Rensselaer
Polytechnic Institute
Troy,
New York 12180
Abstract- There
is currently a large research effort underway to develop new techniques and
methods for the efficient development of software. However, much of this effort ignores the vast sum of knowledge
that has been acquired through our experiences in the field of engineering CAD,
especially in the area of VLSI design.
Much of what has been learned in this area centers on database support
for the design process, and in particular, efficient object-oriented modeling
techniques for design data. We believe
that the data model for software is the central issue surrounding the
development of CASE systems. After
comparing the nature of the design process in the fields of VLSI and Software,
a semantic data model for supporting software development is presented.
Keywords-
Software reusability, CAD Databases, Software Engineering, CASE
1
Introduction
Engineering CAD applications and designers
have at their disposal a host of tools to assist in the development of their
products. The experience that these
designers have with CAD/CAM systems has demonstrated that good application
tools contribute greatly to the design process. With this in mind, recent work has been to develop similar tools
for software engineering. Early efforts
in this area indicate that many of the same advantages that were realized by
the users of engineering CAD systems can be found using a CASE system for the
development of software. However, since
the software design process is less well understood than that of other engineering
disciplines, much work remains to be done.
One thing that has been learned is that
there are many benefits to using an underlying database to organize the large
quantities of data typically managed by a CAD environment. However, many CAD tools have employed
conventional database systems in this role, only to discover that the
relational data model on which they are based cannot gracefully represent
engineering design data. It is
necessary to view this data as a set of design objects, and new models for
design data based on this object-oriented concept were developed.
If an object-oriented database supported
design tool is to be effective, it has to represent application data in a form
that matches the user’s conceptual view of the data. This requires that these tools be built around a semantic data
model that is appropriate for the application.
Therefore, at the core of these tools is a data model that mirrors the
design of the final product.
This paper concentrates on data modeling
requirements for software engineering.
Section 2 provides a synopsis of the advantages of applying database
technology to engineering design environments.
Section 3 motivates the application of CAD research to the domain of
software engineering. In Section 4,
some of the problems that are largely unique to software engineering are
discussed. A review of current CAD
modeling techniques such as complex objects and molecular objects is provided
in Section 5. In Section 6, our data model
for CASE applications is shown and explained.
Section 7 addresses how this model relates to object-oriented
programming and design doctrine.
Finally, Section 8 discusses some of the implementation issues faced in
the development of a software engineering environment based on this model.
2
The
Argument for Database Support of CAD and CASE
As engineering CAD systems have developed,
at some point all have had to address the problem of managing large quantities
of design and administrative data. As
the design and size of the project grows, so does the average response time for
basic operations. This dictates the
need for efficient access to design data for the purpose of updates as well as
for the generation of reports and other documentation. Developers of CAD systems quickly realized
the advantages of capitalizing on readily available database technology, and
applied such indigenous database features as file indexing, standard query
language capabilities, and controls on access to data for concurrency and
security reasons.
3
The
Correspondence Between VLSI CAD and CASE
Most of the research and current
literature involving engineering CAD systems has centered on VLSI
applications. The goal of this project
is to adapt what has been learned in the field of VLSI here at RPI [Har87a,
Sam87] and elsewhere [Bat85, Bro84, Buc85, Gut82, Has82, Kat85] to the domain
of software development [Pou88]. The
motivation is not only the desire to use as much of what is already known as
possible, but the realization that there is a series of basic design problems
that are the same; namely, version control, the large quantities of data, and
the reuse of existing components.
Furthermore, both VLSI and software development generally employ a
hierarchical design process, using stepwise refinement as a means of reducing
the problem to pieces of manageable size.
Finally, both processes employ various graphical tools to assist in the
design. The tools not only aid the
designer by providing a spatial representation of a design object, but may
allow the designer to view the problem from different perspectives, such as the
logical function of a circuit versus its physical layout.
4
Special
Requirements of CASE
There are several problems that are
present in the development of software that do not arise in VLSI design. A large portion of these is derived from the
fact that software is primarily composed of ideas and algorithms, in contrast
with a VLSI component that is both conceptually and physically more
concrete. In a sense this makes the
design and manufacture of VLSI components “easier,” and therefore extensively
studied and well defined.
The first issue that is adversely affected
by this is the reusability problem [Rei87, Weg84]. At low levels, both VLSI components (adders, shifters, and
registers) and software components (stacks, queues, and searching routines) are
fairly standardized and are quite well understood. Therefore, they can be easily classified. However, where concepts and algorithms
predominate at the higher levels of design, the categorization of components
becomes much more abstract. This problem
is especially true in the case of software.
Of course, effective reuse depends on the ability to access available
components. What is required is a
catalogue of design objects based on some universal criteria or keywords
[Onu87], a subject that is currently getting much attention [Bur87,
Pri87]. A CASE system would then be
able to use these keywords to assist the program designer in locating related
and potentially reusable components.
An additional problem caused by the
greater abstraction in software design is that there remains the need to
manipulate large quantities of text. In
a typical VLSI CAD application, the user rarely deals with chip geometries and
layouts directly in file form; rather, he completes his design almost totally
in a graphic manner.[1]
In software, the final product is composed
of text, and although there is currently a lot of work being done in the area
of graphical programming [Bal85, Rae85], there exists a point in the software
design process when this fact must be addressed. In short, the CAD system does a better job at hiding the details
of the actual physical design representation, an ability that should be
extended to the design of software.
Another problem found in software is the
management of an infinite number of possibly very complex data types. In contrast, data types in VLSI tend to be
few and are better defined, (for example, simple bits, or combinations of bits
into bytes or words). Some of these bit
combinations may be in a specified format such as integer or real, but the
complexity of these formats does not rival the intricate data structures found
in structured programming languages.
Any CASE system must be capable of handling this diversity of data.
Finally, wherever a VLSI circuit is needed
in the final product, a copy of it is made and burned onto the chip. This instantiation of the design object does
not apply to software, where only one copy of a module may exist at any time. In VLSI CAD, a reference to an object during
the design stage results in a copy of the physical object later. In software, references to an object during
the design stage remain references to a single copy of that object, even in the
final product.
5
Existing
Database Support for CAD Systems
5.1 For VLSI
Although many VLSI CAD systems exist and
have been supported by relational databases, it is now well recognized that the
standard relational database is inadequate for modeling and storing design data
[Bat84, Has82, Hel87, Sid80]. To meet
the need for a powerful and straightforward representation of design objects,
complex objects and object-oriented database systems were developed [Kim87,
Lor83]. Complex objects are
hierarchical groups of tuples consisting of a root tuple that represents a data
object, and a set of dependent tuples that define the object. Complex objects can succinctly represent the
recursive, non-disjoint objects that the relational model cannot easily handle
[Bat84, Buc85].
The molecular object model is an example
of a semantic data model for design data that is based on complex objects.
In this model, objects are defined to have
two distinct parts, an interface and an implementation [Bat85, Kat85]. As shown in Figure 1, the interface of an
object consists of connections to the outside world, and defines how
other objects can use or access the design object. It contains the common attributes of the existing implementations
for that object. The implementation of
the object defines how the object does its job, and in VLSI is typically
made up of instances of sub circuits and the wires that interconnect them.
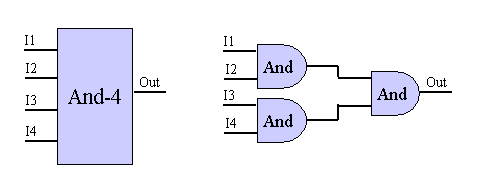
Figure
1. A 4-input AND gate.
When using the molecular model, a designer may refer to a sub
circuit without specifying an implementation for that sub circuit. In this
case, the designer references only the interface for the object. If the designer does not bind an
implementation to this interface, the interface is referred to as a socket in
the design of the higher-level circuit.
This socket must then be plugged with an implementation for that
interface before the design can be considered complete. The plug becomes an instance
of the subcircuit in the design.
5.2 For Software Engineering
To date, software engineering database
support has been primarily provided by relational systems [Gut82, Rou83]. This is especially true with regards to
commercially available environments.
Papers on object-oriented database support for software engineering tend
to concentrate on the functionality and requirements of the final product
[Ber87, Rom87, Yau87]. So while there
are many existing CASE systems, there is not a lot of research focusing on data
modeling problems. However, the data
model is a central issue that should motivate the design of the entire CASE
system. For this reason, we have
developed an object-oriented data model for software, and are currently
implementing a CASE environment based on this modeling concept on DEC
VAXstations using the ROSE engineering database system.
ROSE is an experimental database system
that provides graphics and user interface abilities for CAD applications.
ROSE is fast, manages data clusters as
objects, and provides access to the database through a combination of powerful
control structures based on the ‘C’
programming language and database commands that are an extension of the
relational algebra [Har87a, Har87b].
Additionally, data structures in ROSE are defined in an expressive
AND/OR tree format [McL83].
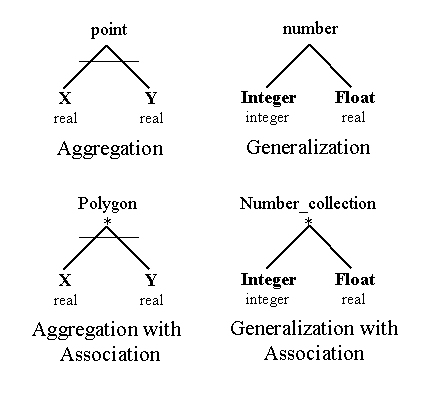
Figure
2. The Four Types of AND/OR Trees.
Each node in an AND/OR tree defines a
domain for an object or one of its sub-objects. AND nodes represent aggregation abstractions, OR nodes represent
generalization abstractions [Smi77], and an asterisk under either type of node
represents an association abstraction [Bro84]. Figure 2 contains examples of
these abstraction types.
6
A
Data Model For CASE
The primary
concern in developing a data model for CASE is that it must address the issues
of design data capture, classification, and retrievability discussed above, and
it must be supportable by an underlying database system. It must also give consideration to the
practical requirements of implementation, and any possible restrictions on
access time and memory management. In
our model, the software module is considered the basic design object. The model is strongly influenced by the
molecular object model of Batory because of a natural correspondence between
the molecular view of VLSI circuits and object-oriented view of software
modules. First, there is the similarity
between the VLSI interface, which is composed of a list of pins, and the
software interface, which is composed of a list of parameters. Second, there is the correspondence between
the VLSI implementation, which is composed of gates, sub circuits, and wires,
and the control statements, calls to subprograms, and flow of control found in
the implementation of a software module.
Our data model extends the two-part molecular model in order to fully
support the unique requirements of the software design process.
The following modifications to the
molecular model are required for use in a CASE system. First, the concept of instantiation needs to
be adapted to mean a reference, and not a copy. Second, in the molecular model the interface
of the object is used in two distinct roles, one in the definition of the object
and one in the definition of a socket, which is a call to an object. We argue for dividing the interface portion
of the data model into two parts in order to accommodate this conflict.
Modification of the concept of
instantiation is required in order to clarify the notion that in the final
software product, just as in the software design, only one copy of a design
object exists. Calls, or instances of
the design object, are references to a software module; during execution of the
program a call to a module results in the transfer of program control to the
physical location of that routine. In
VLSI design, an instance of a design object is a reference to a single
copy of the design specifications for that circuit. However, in the final hardware product, every instance of
a sub circuit in the design results in a copy of that circuit being created and
placed on the chip. This view of
instantiation, which implies the creation of multiple copies of the design
object, is not appropriate for software.
The second change to the VLSI model
involves the dual role of the molecular interface. The problem with the interface in the molecular model is that the
interface found in the declaration and the interface found in the module call
are not the same, and, in fact, have completely different functions. The difference is that the interface found
in the declaration represents the object. Since it may represent many alternatives and versions of that
object, there are strict limitations on how the user may modify the
interface. The interface in the module
call, on the other hand, is a request for
service. It differs from the declaration interface
because it evolves with the design, and may not even represent a particular
design object, especially early in the design process. Since the details of the request may change
as the design develops, the second kind of interface should, in a sense, be
more flexible, and provided with operations that help guide the designer
towards satisfying the need for service.
An example of the two ways that a module interface
is used is shown in Figure 3.
The software
interface in the module declaration:
Procedure Sort(Var Variable1: Array[1..100] of integer;
Variable2: Boolean);
The software interface
in the module call:
Sort(Integer__array, Error__flag);
Figure
3. The Two Roles of the Software Interface.
What typically happens is that when a
designer needs a subprogram to perform some function, he first starts with a
partially defined requirements statement representing what he needs to do. With this need in mind, he searches the
software database for available routines.
If he finds an appropriate routine, he incorporates the interface for it
into his design as a subprogram call (socket). If not, he must design his own interface, thereby creating a new
interface object. However, this is
difficult to do given that requirements are often ill defined and likely to
continue to evolve over time. However,
since the molecular model treats definition interfaces and request-for-service
interfaces the same, the designer must fully detail the required interface at
this time. This is required because by
treating the defining interface as common to many implementations, the
molecular model necessarily places a host of restrictions on how they can be
modified later.
What is needed is a meta-interface
that provides a place for the designer to sketch the requirements for a
subcomponent without the need to know exactly what he wants. A new object type, the <f 2>call, is introduced to meet this need. The call
not only has a much more flexible set of operations to allow the interface to
evolve, but it also has an associated set of descriptive keywords and
performance constraints that the designer may use to assist in electing
available components to fill the socket.
The resulting three-part model for
software, termed the Interactive Development Model (IDM), is shown in Figure
4.
The interface portion of the IDM is used
exclusively to describe software modules, and plays the declaration role of the
molecular interface, as shown in Figure 3.
The alternative portion of the model is also used exclusively for
describing the software module; however, the alternative defines the code and
other implementation details of the module.
The final portion of the model is the call. The purpose of the call is to describe a request for service in a
sufficiently abstract way, in order to assist the designer to bridge the gap
between requirements and any objects available to meet those requirements. It is important to remember that the call
represents what the designer thinks he needs, where the interface and
alternative objects serve to define the object. For this reason, components of the call, such as the parameter
list, are tentative and modifiable, where in the interface and alternative they
define a module and may not, in general, be changed. Other parts of the model and their function are described below.
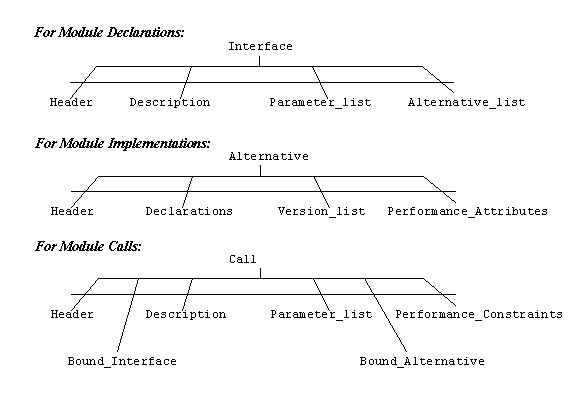
Figure
4. The Data Model for Software
The “Header” fields contain the object
name and other administrative data about the object, such as the name of the
responsible designer and the date the
object was created. The “Description”
in the interface and the call portion of the object consist of general comments
and a set of keyword identifiers. These
keyword identifiers are used in the call to outline the call’s required
service, and serve as search parameters into the library of interfaces, where
the keywords tell the user the attributes of each interface. The “Performance__Constraints” in the module
call correspond to the “Performance__Attributes” of each alternative
implementation. As in searching the
software library for interfaces based on the keyword identifiers, suitable
alternatives of an interface are located in the library based on the call’s
stated constaints on performance and on each alternative’s ability to meet
those constraints.
The addition of the call object to the
molecular data model has an important consequence for the reuse of design
objects. Because there are criteria
available to link requests for service with routines potentially able to meet
them, the filling of module calls (sockets) should and can be automated. In
many cases this may even be left until the design is compiled or
validated. At that time, the program
that compiles the design will have three sets of criteria on which to base the
selection of an appropriate module to fill the call. First, the initial description of the call provides keywords that
partially identify an interface.
Second, the parameter list in the call is compared with the parameter
lists in the potential interfaces in both number and type of parameters. At this point, if there are candidate
routine(s), an interface for the call is identified, or at a minimum narrowed
to a few choices that the designer may easily browse. Finally, the performance constraints specified in the call are
matched against the performance attributes of the alternatives for the identified
interface in order to provide a final selection of implementation.
The “Bound” fields in the call object
allow the designer to save the name of an interface or alternative once he has
located one that will fill the call.
Note, however, that with the IDM it is possible for objects filling a
call to be referenced explicitly as a specific reference, or implicitly
according to some default criteria. The
designer has the option of which type of assignment to make. A temporary, or implicit, assignment would
be used if he always wanted to fill the call with the latest version of a given
alternative. An explicit, or permanent,
assignment would be warranted if, for example, he specifically wants version
V1.2 of “Binary__sort” to fill a given call.
This matching of constraints with performance
criteria and the use of dynamic binding of calls with components makes the IDM
particularly effective for use for an evolutionary design process. The advantages of dynamically binding design
objects to sockets have also recently been recognized by Dittrich and Lorie
[Dit88]. While their solution defines
and stores “environment” characteristics that will be used at run time to
qualify candidate objects for sockets, we feel that for conceptual clarity it
is better to incorporate this and all other design-related information directly
into the design data.

Figure
5. Object Hierarchy.
Control of versions and alternative
implementations is accomplished in the data model through the use of
association abstractions (multiple reference pointers) from one part of the
model to the others. The relationships
between these objects are defined in the Entity-Relationship diagram of Figure
5. A design object, which in our case
is a software module, has exactly one interface. The interface is stored as an Interface object as defined in
Figure 4, and may have any number of alternative implementations in the
design. While the differentiation
between alternatives of an interface is left to the user, they are typically
distinguished by a fundamental difference in algorithm. These alternatives are related to the
interface by means of forward pointers in the association abstraction called
“Alternative__list.”
Each alternative implementation is
represented in the database by the Alternative object of Figure 4. An alternative may be composed of any number
of versions, which are snapshots of the alternative, usually as it evolved over
time in response to bugs or minor changes.
The version of the alternative contains the pseudo-code representation
of the module’s function, and is accessed through the association abstraction
“Version__list.” It is worthwhile to
note that other related concepts, such as configurations (implementations for
some specified purpose such as site requirements), are easily incorporated into
the model as alternatives.
7
Relationship
to “Object-Oriented” Program Design
One of the most important aspects of the
object-oriented design paradigm is the encapsulation of certain parts of the
design in order to hide implementation details from the user [Boo84, Pyl81,
Wir85]. In this context we define
“object-oriented” not in the Smalltalk sense but rather in the Ada sense, as
data and related operations encapsulated or packaged so as to be invisible to
and protected from the user. However,
care must be taken in object-oriented design so that during the design process
certain key data remains accessible.
Much of the information that the designer requires in order to (i)
retrieve appropriate design objects from the database, and (ii) select the best
implementation for his needs, is specific to the implementation and is not
available by looking solely at the interface for that object.
The data model above reflects the belief
that, although one part of the object’s interface is, indeed, composed of the externally
visible attributes common to all its implementations, the complete
interface must provide access to all the externally visible attributes
of a module, even those that are implementation-specific. The primary examples of such attributes are
performance characteristics that may influence a designer’s decision to use
that object, such as those required in order to conform to a set of design
constraints. Other such attributes
include memory requirements, object code size, and the time complexity of the
algorithm. In the VLSI domain, such
attributes include surface area, power consumption, and delay time.
8
Implementation
in ROSE
The complete ROSE implementation of a CASE
system based on this data model includes several graphical editors for design data
input, a combination of pull-down menus and text-entry boxes, and mouse-driven
icons. These interface considerations
are techniques designed to assist the designer as he interacts with the system
and uses the reusability features that are built into the model. A sample session with the ROSE CASE Tool is
shown in Figure 6.
For support of reusability, a common set
of descriptors for the software library and the performance attributes of the
library components has been defined.
These descriptors are based largely on the work of [Pri87] and [Bur87]
and are used as keys during searches of the software library.
Screen
shot not available.
Figure
6. Sample Session with the CASE Tool.
First, in order to reduce the amount of
text entry and to distance the user from the details of the data model, the
CASE system provides real-time graphic tools to support the design
process. Several major software design
methods, including data flow, data structure, and structured design, were
considered for this purpose [Ber85].
Mappings from these methodologies to program structure are well defined
[Jac75, Mye78, You75], and are used to dynamically capture graphical edits made
by the designer. These edits are stored
in a pseudocode-type format. This is
possible because the ROSE AND/OR tree description of the data model mirrors the
Backus-Naur descriptions used by many of the major structured programming
languages. This AND/OR tree description
is also used to describe the multitude of data structures available to the
software designer.
Screen
shot not available.
Figure
7. The CASE Tool Dynamic Structure Editor Options.
As a example of how the designer uses the
tools to develop an abstract request-for-service into a specific module
instance, consider the case where the software designer has a need for some
kind of sorting routine. Using the edit
options provided in Figure 7, he adds a generic call to the design, graphically
portrayed in the Dynamic Structure Editor by a Call icon.

Through the use of a set of text-entry
tools, the designer has tagged this call icon as some kind of sort. Using the same text-entry tools, he now
consults the public software library for possible routines that might be
available for his use. After querying
the software library he discovers an existing interface for an integer array
sort that appears as if it will serve the function he requires. Content with this possibility, he binds the
interface to the call and proceeds to investigate possible alternative
implementations for this interface. The
graphical editor responds by replacing the call icon with an interface icon.
Again using the text-entry and searching
tools, the designer finally uncovers in the library a quicksort version of the
interface that he prefers to use, based on his particular time constraints,
memory use, and other considerations.
He binds this alternative to the call and thus fulfills his original
software requirement. He could just as
easily copied the existing software into his workspace and mode modifications
to the code if it were necessary. As
shown below, the graphical editor now replaces the interface icon with an
alternative icon, thereby representing the fact that the call has been plugged
with defined components.
9
Conclusion
In light of the numerous advantages of
database support for the engineering design process, much research has gone
into applying this technology to CAD, especially with respect to VLSI
design. Little, however, has been done
to use this knowledge in the design of software. We have identified several of the important similarities as well
as some significant differences in the two domains. These include the question of reuse of program modules, version
control requirements, and textual versus graphical representations. We have demonstrated a data model
specifically for use in
CASE that addresses these issues, and
identified valid operations on the model.
The three-part Interactive Development
Model separates the interface portion of the molecular object model into two
parts. These two parts reflect the two
different roles that an interface has in the semantic representation of design
data. First, the interface defines and represents the object. Second, the call is used to a request service
from the object. Finally, the third
part of the data model is the alternative implementation of the object. Operations on this model are identified in
the appendix and are adapted to the roles each part of the model plays in
representing the software module. Also,
while this data model was specifically developed for use in a software
engineering environment, much of this concept applies equally well to
engineering CAD/CAM applications.
Implementation of the prototype CASE
environment based on these modeling ideas is well underway. Several graphical editors are provided,
including a Structured Diagram editor, a program structure editor, and a
variety of formatted text entry tools.
A comprehensive query facility is provided and activated through a series
of pull-down menus and mouse-driven icons.
Special emphasis has been placed on providing flexible access to the
reusability characteristics built into the model.
Future work will focus on completing the
prototype CASE system. As this work
continues, we will be addressing various questions involving user interface
considerations for flexible, efficient access to the data model, as well as
special application area topics such as might be required in an operating
systems environment. Special support
for animation of control flows and data flows are also being explored. Such a capability will allow the designer to
receive a visual demonstration of how the design will perform or react to
particular modifications.
10 Acknowledgements
We gratefully acknowledge the many
contributions made by David L. Spooner in the preparation of this paper. We would also like to acknowledge the help
of Margarita Rovira in providing diagrams for the text. This work was partially supported by a grant
from the International Business Machines Corporation, Meyers Corners, New York.
Appendix: Operations
On Interfaces-
- create__new__interface: this
creates a template for a new interface in the workspace and allows
unrestricted modification. When
complete, the interface is “frozen” and becomes the definition for a new
object.
- create__from__existing: this copies an existing interface into
the workspace and allows unrestricted modification. When complete, the interface is frozen
and becomes the definition for a new object.
- retrieve__interface: fetches a specific interface from the
database library using the interface name as a key.
- search__for__interfaces: assists the designer in locating
interfaces in the database library using keyword search or parameter matching.
- bind__interface: associates the interface with a call in
the program design.
- display__alternatives: allows the designer to browse the
alternative implementations for a given interface.
- delete__interface: removes the interface from the library.
To prevent orphan alternatives,
this operation is disabled if there are alternatives for the interface
remaining in the database.
On Calls-
- create__call: creates a template for a new call in
the workspace.
- copy__from__existing: retrieves an old call using the
retrieve__call option and copies the call into the workspace.
- retrieve__call: fetches a specific call from the
database using a surrogate tuple identifier as a key.
- make__call: assigns a location for the call in the
code of an alternative.
- unmake__call: removes a call from the code of an
alternative.
- unbind__interface: disassociates a bound interface from
the call. If an alternative for
the interface is also bound to the call, unbind__alternative is
automatically invoked.
- unbind__alternative: disassociates a bound alternative from
the call.
- delete__call: removes a call from the database.
- update__call: allows near-unrestricted modification
of the call.
- fill__call: automatically locates interfaces and
alternatives that may match a call using full or partial matches on the
call keywords, parameter list, and performance constraints. If no modules meeting the criteria are
available, it advises the designer.
On Alternatives-
- create__alternative: creates a
template for a new alternative in the workspace. The new alternative contains a null version of the
object.
- create__from__existing: copies an existing alternative into the
workspace using (interface__name, alternative__name) as a key.
- retrieve__alternative: fetches an existing alternative from
the database library using (interface__name, alternative__name) as a
key.
- search__for__alternatives:
assists the designer to locate alternatives in the library using
implementation specific data such as designer name, modification dates,
and performance attributes.
- bind__alternative: associates the alternativewith a call
in the program design.
- update__alternative: allows modification of the
alternative. Normally, a new
version number is assigned and the modification log updated.
- display__versions: allows the designer to browse the
versions of an alternative.
- delete__alternative: removes an alternative from the
database.
11 References
[Bal85] Balzer, Robert. “A 15 Year Perspective on
Automatic Programming,” in IEEE Transactions on Software Engineering,
Vol. SE-11, No. 11, November 1985, pp. 1257-1268.
[Bat84]
Batory, D.S. and Alejandro Buchmann, “Molecular Objects, Abstract Data Types,
and Data Models: A Framework,” in Proceedings of the 10th International
Conference on Very Large DataBases, Signapore, August, 1984, pp. 172-184.
[Bat85]
Batory, D.S. and Won Kim, “Modeling Concepts for VLSI CAD Objects,” in ACM
Transactions on Database Systems, Vol. 10, No. 3, September 1985, pp.
322-346.
[Ber85]
Bergland, G.D. “A Guided Tour of Program Design Methodologies,” in IEEE
Tutorial on Software Quality Assurance, ed. Tsun S. Chow, IEEE Computer
Society Press, Silver Spring, Maryland, 1985, pp. 219-243.
[Ber87]
Bernstein, Philip A., “Database System Support for Software Engineering: An
Extended Abstract,” in Proceedings of the 9th International Conference on
Software Engineering, Monterey, California, April, 1987, pp. 166-178.
[Boo84]
Booch, Grady. Software Engineering with Ada, 2nd. ed. The
Benjamin/Cummings Publishing Company, Inc, Menlo Park, California, 1984.
[Bro84]
Brodie, M., B. Blaustein, U. Dayal, F. Manola, and A. Rosenthal, “CAD/CAM
Database Management,” Database Engineering, Volume 7, Number 2, 1984.
[Buc85]
Buchmann, Alejandro P. and Concepcion Perez de Celis, “An Architecture and Data
Model for CAD Databases,” in Proceedings of the 11th International
Conference on Very Large Data Bases, Stockholm, 1985, pp. 105-114.
[Bur87]
Burton, Bruce A., Rhonda Wienk Aragon, Stephen A. Bailey, Kenneth D. Koehler,
and Lauren A. Mayes, “The Reusable Software Library,” in IEEE Software,
July, 1987, pp. 25-33.
[Dit88]
Dittrich, Klaus R. and Raymond A. Lorie, “Version Support for Engineering
Database Systems,” in IEEE Transactions on Software Engineering, Vol.
14, No. 4, April 1988.
[Gut82]
Guttman, Antonin and Michael Stonebraker, “Using a Relational Database
Management System for Computer Aided Design Data,” in Database Engineering,
Vol. 5, No. 2, June 1982, pp. 21-28.
[Har87a]
Hardwick, Martin, George Samaras and David Spooner. “Evaluating Recursive
Queries in CAD Using an Extended Projection Function,” in Proceedings of the
3rd International Conference on Data Engineering, Los Angeles, California,
February, 1987, pp. 138-148.
[Har87b]
Hardwick, Martin. “Why ROSE is Fast: Five Optimizations in the Design of an
Experimental Database
System
for CAD/CAM Applications,” in Proceedings of ACM SIGMOD, San Francisco,
California, May, 1987, pp. 292-298.
[Has82]
Haskin, Roger and Raymond Lorie, “Using a Relational Database System for
Circuit Design,” in Database Engineering, Vol. 5, No. 2, June 1982, pp.
10-14.
[Hel87]
Helier, Sandra, Umeshwar Dayal, Jack Orenstein, and Susan Radke-Sproull, “An
Object-Oriented Approach to Data Management: Why Design Databases Need it,” in Proceedings
of the 24th Design Automation Conference, Los Vegas, Nevada, 1987, pp.
335-340.
[Jac75]
Jackson, Michael. Principles of Program Design. Academic Press, 1975.
[Kat85]
Katz, R. H. Information Management
for Engineering Design.
Springer-Verlag, Berlin, FRG, 1985.
[Kim87]
Kim, Won, Hong-Tai Chou and Jay Banerjee, “Operations and Implementation of
Complex Objects,” in Proceedings of the3rd International Conference on Data
Engineering, Los Angeles, California, 1987, pp.
626-633.
[Lor83]
Lorie, Raymond and Wilfred Plouffe, “Complex Objects and Their Use in Design
Transactions,” in Proceedings of Annual Meeting of Engineering Design
Applications, San Jose, California,
May 1983, pp. 115-121.
[Mcl83]
Mcleod, D, et al., “An Approach to Information Management for CAD/VLSI
Applications,” in Proceedings of ACM Database Week, SIGMOD Conference,
San Jose, California, May 1983.
[Mye78]
Myers, Glenford J. Composite/Stuctured Design. Van Nostrand Reinhold
Company, New York, 1978.
[Onu87]
Onuegbe, Emmanuael O., “Database Management System Requirements for Software
Engineering Environments,” in Proceedings of the 3rd International
Conference on Data Engineering, Los Angeles, California, 1987, pp. 501-509.
[Pou88]
Poulin, Jeffrey S., “Object-Oriented Database Support for Computer Aided
Software Engineering,” Research Summary, Department of Computer Science,
Rensselaer Polytechnic Institute, February, 1988.
[Pri87]
Prieto-Diaz, Ruben, and Peter Freeman. “Classifying Software for Reusability,”
in IEEE Software, Los Alomitos, California, January 1987, pp. 6-16.
[Pyl81]
Pyle, T.C. The Ada Programming Language.
Prentice-Hall, Englewood Cliffs, New Jersey, 1981.
[Rae85] Raeder, Georg. “A Survey of Current
Graphical Programming Techniques,” in IEEE Computer, Vol. 18, Number 8,
August 1985, pp. 11-24.
[Rei87]
Reilly, Angela. “Roots of Reuse,” in IEEE Software, Los Alomitos,
California, January 1987, pp. 4-5.
[Rom87]
Roman, Gruia-Catalin, “Data Engineering in Software Development Environments,”
in Proceedings of the 3rd International Conference on Data
Engineering, Los Angeles, California, 1987, pp. 85-86.
[Rou83] Roussopoulos, Nick and Stephen Kelly, “A Relational Database to Support Graphical Design and Documentation,” in Proceedings of annual meeting of Engineering Design Applications, San Jose, California, May 1983, pp. 135-149.
[Sam87] Samaras, George and Martin Hardwick, “User
Manual for a VLSI CAD System Developed on ROSE,” Department of Computer
Science Technical Report, Rensselaer Polytechnic Institute, Troy, New York,
pp. 1-24.
[Sid80] Sidle, Thomas W., “Weaknesses of Commercial Data Base Management Systems in Engineering Applications,” in Proceedings of the 17th Design Automation Conference, New York, 1980, pp. 57-61.
[Smi77] Smith, J. and D. Smith, “Data Abstractions: Aggregation and Generalization,” ACM Transactions on Database Systems, Volume 3, Number 3, 1977, pp. 105-133.
[Weg84]
Wegner, Peter, “Capital Intensive Software Technology,” IEEE Software,
Vol. 1, Number 3, July 1984, pp. 7-45.
[Wir85]
Wirth, Nicklaus. Programming in
Modula-2. Springer-Verlag, New
York, 1985.
[Yau87] Yau, Stephen S. “Relationship Between Data Engineering and Software Engineering,” in Proceedings, 3rd IEEE International Conference on Data Engineering, Los Angeles, California, 1987, pp. 84.
[You75]
Yourdon, Edward. Techniques of
Program Structure and Design.
Prentice-Hall, Inc., Englewood Cliffs, New Jersey, 1975.