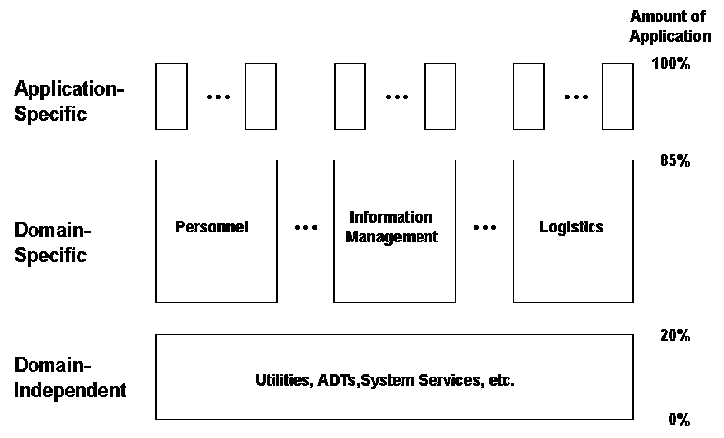
Figure 1: The Three Classes of Software
Date: 17 January 1996
This article describes a Software Architecture for applications in the domain of Management Information Systems (MIS). It describes four views of the software architecture in terms of the architectural concepts introduced by Garlan and Shaw. Designed to comply with Open Systems Environment (OSE) standards and in use today on one of the U.S. Army' largest information systems, this architecture has led to unmodified component reuse levels of over 20% on the first 7 applications.
Software architectures provide many benefits, ranging from documenting a common framework which developers use to build application programs to standardizing a program's approach to reuse and maintenance. A good software architecture serves as the reference and starting point for all software discussions and designs. Because the architecture tells developers how to start building an application, it aids in training new developers while at the same time keeping all developers working towards the same ultimate goal.
This paper describes a reuse-based software architecture for applications in the MIS domain. The architecture implements the need for a flexible framework that can evolve and adapt to the changing requirements and environment faced by the Army customer. These requirements include the need to support client-server style applications in a dynamic environment which may have severe constraints on security and network bandwidth. This paper takes many of the abstract concepts surrounding architectures, such as integrating reusable components of both applications and data, and shows how a major software initiative applies these concepts through tools and software.
We developed the architecture described in this paper for the Sustaining Base Information Services (SBIS) program. SBIS represents a 10-year contract potentially worth $474 million to improve and standardize the Army's automation of day-to-day business functions. SBIS will overhaul the administrative functions carried out at Army installations by providing hardware, networks, and software applications in areas such as logistics, finance, personnel, and training. The system allows the Army to move from proprietary operating environments to open systems standards-based configurations, and provides a procurement vehicle for the rest of the Department of Defense (DoD).
SBIS must comply with Open Systems Environment (OSE) standards as specified by the National Institute of Standards and Technology (NIST). The defining documents for these standards largely come from the IEEE POSIX documents as restricted by the appropriate Federal Information Processing Standards (FIPS). The Defense Information Systems Agency (DISA) has further codified the standards by relating them within a Technical Architecture for Information Management (TAFIM) [3]. SBIS has committed to supporting these standards as well as their refinements in the Army C4I Technical Architecture [2].
We begin our discussion of software architectures with a brief overview of the work of David Garlan and Mary Shaw [5]. Garlan and Shaw define architectures as consisting of three major items:
We describe the software architecture using a set of four views, or technical perspectives of some aspect of the architecture [10], by giving the details of each view in terms of Garlan and Shaw's components, connectors, and constraints. Components fall into one of several categories of objects:
Connectors in an architecture define the interactions between architectural components. In SBIS, connectors between objects will primarily take place via Remote Procedure Calls (RPCs); however, objects can also embed other objects and can communicate via the database. Although the current applications do not use RPCs, we have the strategic objective of using Distributed Computing Environment (DCE) RPCs as soon as an Ada binding to DCE RPCs becomes available.
An extensive list of configuration rules comprise the constraints upon the software architecture. Rules give the MIS developer specific guidance on how to implement the architecture by explaining how to make connectors between components and by codifying the principles behind the architecture. We discuss the relationship between these aspects of a software architecture below.
To understand the basis of the software architecture we start by explaining the different classes of software that make up a typical MIS. As in other domains, most programs make use of a standard set of domain-independent, general-purpose utility software. As shown in Figure 1, this utility software provides a good example of horizontal reuse, or reuse across domains. Most programmers have experience in horizontal reuse by way of mathematical subroutines or I/O libraries. Although horizontal reuse has stable and low risk benefits, these benefits have upper limits of around 20% of an application due to the generally small size and scope of domain-independent software [9].
Figure 1: The Three Classes of Software
Vertical reuse, on the other hand, takes place within a domain or a family of related applications. Vertical reuse has a tremendous potential benefit when building many applications within a related area or domain because each application can make use of common objects and operations. As an example of the benefits of domain-specific reuse over horizontal reuse, the estimated reuse potential in the domain of business applications (management information systems) ranges from 75% to 90% [7]. To achieve these levels of reuse an application must make use of domain-specific frameworks and software.
Figure 2 depicts how these classes of software contribute to the design of the software architecture. This figure shows what processes might run on a typical computing platform, or process server. Note the domain-independent Service Objects that provide functions common to "most" or all MIS applications. The picture shows that if a developer in the software domain of Resource Management needs 8 major functions to build an "Logistics" application, 3 of the 8 may already exist as reusable Service Objects. Likewise, if a developer of a "Personnel" application needs 6 major functions, 3 may already exist.
The development team has already identified and constructed about 30 Service Objects to run in the horizontal reuse layer. These objects provide services ranging from scheduling to audit trail and print functions. Of the approximately 1.2 million lines of source code in the first 7 applications, Service Objects make up over 20% (Reuse% [8]) of the software for a conservative estimated Reuse Cost Avoidance (RCA) [8] of approximately $7 million.
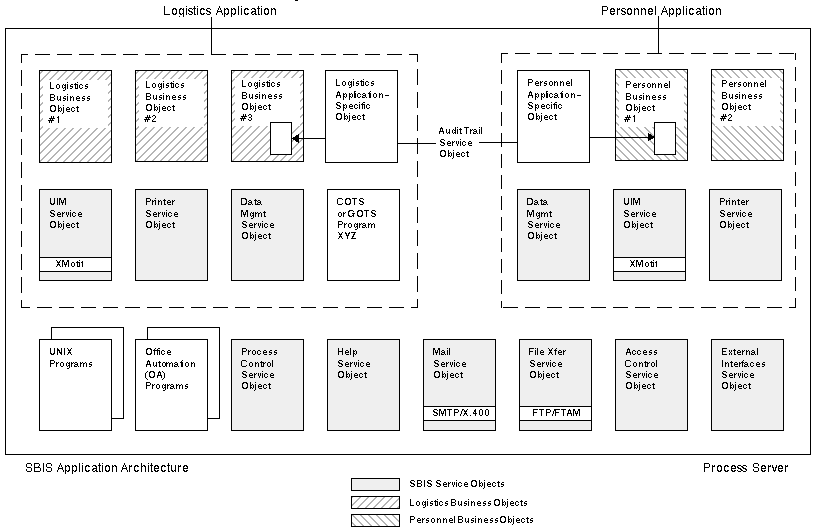
Figure 2: Service Objects and Business Objects Provide Common Functions.
Figure 2 also shows the client-server nature of the architecture; note that some objects running on the process server do not directly support either of the two applications. These Service Objects act as servers to all applications, running in the operating system background environment ready to accept a request for service from one of the running applications or from a new application. For example, when a user invokes a new application the Process Control Service Object receives the message and responds by establishing the environment needed by the newly-invoked application.
The development team has recently completed a pilot domain analysis of the SBIS (sub-)domains. As a result of this analysis we plan to construct domain-specific frameworks for each domain. Each framework consists of components for use within the domain, rules and interfaces defining how to connect the components, and perhaps tools to help developers assemble applications using the domain-specific components and rules. The framework contributes to vertical reuse by providing families of reusable components for use within each domain. We call these components Business Objects.
Figure 2 shows that 2 of the 6 functions required for the example Personnel application exist as Personnel Business Objects. The figure also shows that of the 8 functions required for the Logistics application, 3 already exist as pre-built Logistics Business Objects. In fact, because 2 of the first 7 Applications fell within the domain of Resource Management, we identified and built Resource Management Business Objects so that the 2 applications could share about 24% of their code.
The architecture provides the means to achieve high levels of reuse through the use of common services and domain-specific functions. To complete the application, it only remains for the developer to provide the glue code to tie all these reusable functions together and to provide any application-unique logic. We call this remaining code Application Objects.
Having an architecture based on these well-encapsulated, reusable objects allows us to both benefit from and contribute to work done in other programs. We can expect to share (both reuse and provide) useful Service Objects and Business Objects with other MIS programs. This reuse can bring considerable benefits to both SBIS and the DoD.
A comprehensive software architecture must span many areas, each having varying amounts of detail and implementation options. Zachman recommends abstracting these concerns using a comprehensive set of views of the software architecture [10]. The views add the detail necessary to allow the developers and users to understand, describe, use, and consistently implement MIS applications. We describe the architecture using four views: [4]
These views explain the important features of the software architecture as those features appear from that view's perspective. For each view, we identify the major components, connectors, and constraints affecting that view. In the sections that follow, we show how we implement each view in our environment with specific tools and software.
This view of the software architecture reflects the perspective of the developed Ada software, in other words, the logic that implements each application. As shown in Figure 3, the application view depicts five application layers, each of which may contain commercial products, OSE services, and MIS objects. Each layer has a well defined interface to insulate that layer from adjacent layers. At the top of the figure, the user sees the Presentation layer, which consists of the application window on the user's X-station, personal computer, or workstation. Next, the User Interface layer manages and controls the interactions between the presentation layer and the applications. This layer consists of a commercial Graphical User Interface (GUI) development tool (XVT(TM)) as well as a Service Object (the User Interface Manager (UIM)) which abstracts certain aspects of the tool for developers. XVT allows automatic generation of numerous presentation standards (such as MOTIF, Microsoft Windows®, OS/2 Presentation Manager®, character-based interface, etc.) directly from a single GUI description.
The middle layer, Application Processing, primarily consists of the Service Objects, Business Objects, and Application Objects as explained above. The Data Access layer shields the application logic from the data by abstracting both the location and the physical format of data so that it appears to the applications as a single, integrated database. The service object includes an internally developed data management Application Programming Interface (ADM/API) to shield developers from changes in the underlying commercial database products should they occur. Finally, the Data Store layer controls the physical storage of MIS data using structures such as POSIX-compliant files [6} and SQL-compliant commercial database products such as the Oracle® Relational Database Management System (RDBMS).
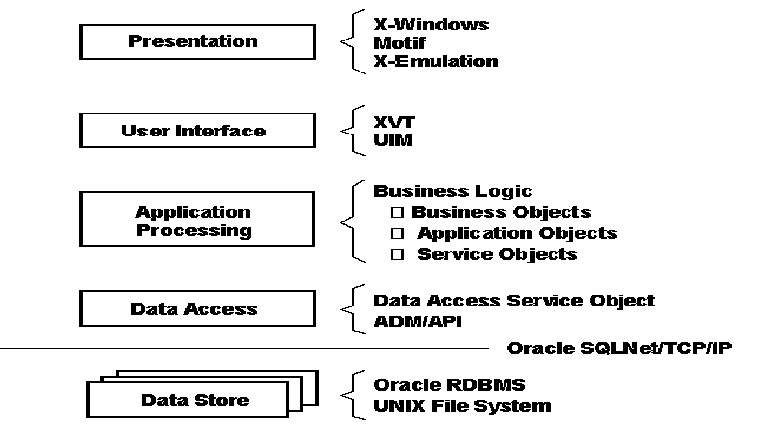
Figure 3: The Application Layered View
The Data View depicts applications from the perspective of accessing, storing, and managing information. The architecture has a key feature in that it presents one integrated logical database to the MIS user. This means that the user need not enter data more than once and it means that the data will remain valid and secure during their life in the database. Applications and the RDBMS enforce access controls over who can read and who can update data, based on guidance from customer requirements and functional users. The applications and database also guarantee data integrity; in other words, once data changes, all users of the data have access to the most recent and consistent information within data synchronization requirements.
Each Army installation has an instantiation of the SBIS Installation Database (SID). Although each SID contains data specific to that installation, each SID instantiation contains the same tables, database definitions, and schemata. This allows maximum reuse of data management assets, thereby reducing development and support costs. In addition to the SID, each Army major command headquarters (MACOM) has a SBIS MACOM Database (SMD) to support headquarters operations. As with the SID, each SMD contains the same tables, database definitions, and schemata. The data within each SMD pertain to a specific MACOM.
Like many large companies and organizations, the Army must support a variety of aging "legacy" systems. Most data enter SBIS in accord with System Interface Agreements (SIAs) made with the owners of these legacy systems. These SIAs specify the types, formats, and frequency of data exchange with the legacy system. Legacy data normally enter at one of two Network Management Offices (NMO) where software utilities divide the data into packages destined for specific sites. For example, when the bulk information arrives at the NMO, it may contain information for all soldiers in the Army. The NMO sorts this information into installation-specific files which contain information on only those soldiers stationed at that installation. The NMO then sends the files to the appropriate installations.
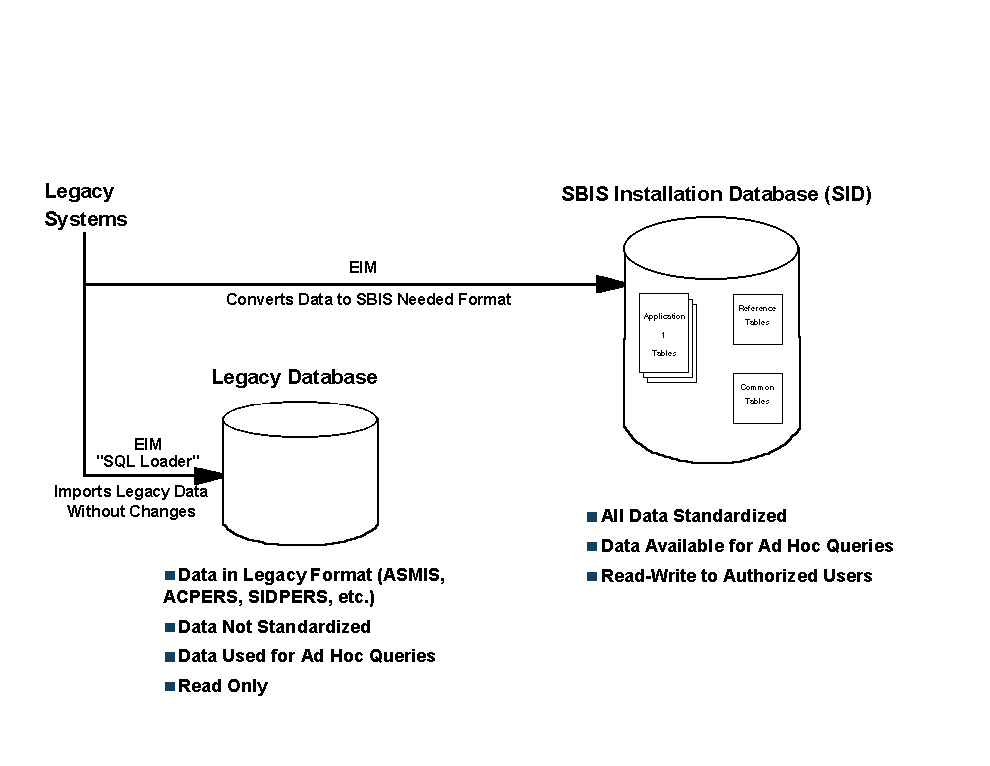
Figure 4: Database Load Process in the SBIS Database
As shown in Figure 4, upon arriving at the installation, a portion of the External Interface Manager (EIM) Service Object loads legacy data into the Legacy Database. This database serves two main functions. Foremost, it provides a holding place for legacy data until the EIM Service Object can extract the subset of the legacy data needed by the applications, convert it to Standard Data Elements, and import the standardized data into the SBIS database. The Legacy Database plays a secondary role of allowing users the ability to issue queries against legacy data in their original form.
The SID consists of relational tables which contain information specific to each MIS application. To support reuse of data as well as application software, the SID database has tables for Common data, or tables containing data shared by two or more applications. For example many applications might share the data element containing a soldier's name and address. Finally, the SID contains tables for shared Reference data. These data differ from common tables in that they contain information such as zip codes and Military Occupational Specialty (MOS) codes that although many applications share, the information does not change often and usually belongs to an agency outside the purview of the program (e.g., the Post Office or the Military Personnel Center).
The Distribution View shows the distribution options for objects and applications within the software architecture. Each layer shown in the Application View, above, shares an interface with adjacent layers which we specify via well-defined, shared Application Programming Interfaces (APIs). The APIs hide the implementation of each layer from the other layers and handle communication between layers. In most instances the layers will communicate via RPC; however, the Data Access and Data Storage layers also make use of distributed database features provided by the database system.
In conjunction with other software, RPCs allow synchronous communication between the fully distributed objects which comprise an MIS application. RPC communication establishes a client-server-based relationship between the three type of MIS objects and gives MIS developers a flexible method of distributing objects. For example, a developer might distribute objects across machines to improve performance characteristics resulting from high network traffic or CPU loads. A developer might also distribute objects or applications across installations to minimize support costs, or simply use RPCs to request information and services from other locations.
The MIS architecture has provisions for distributing application layers, objects within the layers, and entire applications depending on a variety of implementation issues such as performance needs. With other DCE software, the use of DCE RPCs will allow for many of these distribution options while helping to obviate problems such as guaranteeing transaction control, authentication of clients in the client-server model, and security of data as they pass along the network.
Because a developer looks at an architecture and immediately asks "how do I implement this?" we provide a view which tells the developer which tools and methods to use. The Development/Maintenance View of the software architecture details the software development process in terms of component activities of the Software Development Methodology Plan (SWM) and the connecting process flows in the SWM. The backbone of the Integrated Software Engineering Environment (ISEE) consists of commercial requirements management and modeling tools. Although we omit the details here, this view identifies how these tools and methods support the architecture.
Although different views of the software architecture address the concerns of specific classes of users they do not, by themselves, specify the level of detail that developers need to understand what they must do to implement the architecture. For this reason, each view details a list of rules that tell developers what they must specifically do to comply with the architecture.
Architectural rules provide specific instructions to MIS developers and users on how to implement their applications. In effect, these rules become the architectural constraints within which an application must operate. Foremost, the rules provide the maximum amount of detail possible relative to the software architecture. We sometimes refer to this list as the list of "shalls" because it tells programmers what they must do in order to comply with the architecture. For example, architectural rules related to the Application layer of the Application View state:
The culmination of the software architecture comes with its realization in concrete models within the ISEE environment. Specifically, we have provided Essential and Architectural models for users of the MIS architecture. The Essential (Process) Model identifies and defines the business processes which describe application requirements from the user's perspective. It contains data flow diagrams (DFDs), the logical database model, entity-relationship (ER) diagrams, control specifications (C-Specs) for event-driven processes, process specifications (P-Specs) for sequential processes, a data dictionary, and other notes describing the application. The Architecture (Procedure) Model defines how to implement the Essential (Process) Model. It defines the physical distribution of processes that implement the applications; in the SBIS environment it shows where each program process runs on one of our three primary (hardware) processors (end user device, process server, and data server).
These models provide generic templates from which applications can begin their definition and development; they define the allowable configurations of components, connectors, and constraints. In short, applications become instantiations of the MIS software architecture [1]. The architectural models fall under the same configuration management and version control requirements of all products.
This paper describes a Software Architecture for Management Information Systems applications built on the principles of software reuse, client-server operations, and open systems standards. The architecture provides a flexible framework that can adapt to changes in requirements and technology as needs evolve. Future work on the architecture will consist of adding an additional Security View to address security threats and countermeasures of special concern to the DoD. We expect the architecture to evolve as the state of technology and OSE-compliant products develop.
A number of organizations and people have made major contributions to the development of this architecture over the life of the SBIS program. They include not only personnel from Loral Federal Systems, CACI, PRC, and Statistica, but also government representatives from Program Management Office, Sustaining Base Automation (PMO-SBA), the US Army Information Systems Engineering Command (ISEC), and their supporting contractors. This architecture developed directly from the Software Architecture created in 1993-1994 by former SBIS software architects Norm Kemerer and Mike Freeman. We would also like to acknowledge the contributions of members of the MITRE corporation, especially Kevin Heideman and Jeff Hustad, for representing the Army's technical requirements and for selecting and jointly refining the views with which we express this architecture.
Dr. Jeffrey S. Poulin
SBIS Software Architect
Loral Federal Systems
7435 Boston Blvd.
Springfield, VA 22153
Voice: 703-913-1527
Fax: 703-913-3785
E-mail: poulinj@lfs.loral.com