Reuse: “Been There, Done That”
Jeffrey S. Poulin, Lockheed
Martin Federal Systems, Owego, NY
Every regular reader of software engineering literature has surely seen articles that proclaim the many benefits of software reuse. However, while sometimes portrayed as at least one of the elusive software “silver bullets,” reuse has also received a fair amount of negative publicity from those who just do not think it will ever work. I have seen the benefits of successful software reuse programs and want to take a moment to review the lessons learned from those that have “done that.”
Let us look at the many achievements and positive affects that
reuse has had on many practical problems faced by industry. Early work on
library methods gave the field a focus and allowed it to grow. More recently, research on reuse practices,
organizations, domain analysis techniques, and metrics have found a place in
the daily routine of large software development organizations [Poulin97]. Techniques such as object-orientation and
software architectures often rely on software reuse as a unifying goal or
objective. Finally, technologies such
as visual programming (e.g., Visual Basic (VB)) provide a natural medium, such
as “drag-and-drop,” to unconsciously practice reuse. As Ed Yourdon observes,
“the real benefit of languages such as VB/Powerbuilder may be software reuse
rather than the visual paradigm” [Yourdon96].
Overall, I believe that the field of reuse has made considerable
progress.
We have solved the
“Reuse Library” Problem
For much of the past 10 years, reuse has focused on building libraries. We have explored and conquered numerous library issues, such as classification [Prieto-Diaz87] and access mechanisms [Poulin94]. We have discovered that:
· We should concentrate on small libraries of highly used, well-designed, domain-specific, high quality components, and we should avoid large component collections of questionable heritage. The best libraries range from only 30 components to, in rare cases, as many as 250 components.
· In general, users find formal classification methods difficult to use [Mili97]. Collecting large amounts of “meta-data” to help retrieve components wastes time, money, and makes the library both difficult to contribute to and difficult to retrieve from.
· We must provide quality components; the first time someone retrieves a component with a bug from your library will become the last time they use the library. Knowing this, IBM developed a 80,000 LOC collection of highly used software that never experienced a single error [Bauer93].
We have solved the
“Domain Analysis” Problem
The key to high levels of reuse comes from building collections of components that all work together and that many applications will need. We call the problem area that contains these related applications a “domain,” and we call the process of identifying the common components and specifying how they fit together “domain analysis.” Many proven domain analysis methods exist [Arango93]. These methods tend to share a common process consisting of:
1. domain characterization and project planning, which consists of the feasibility analyis and planning steps common to any engineering project,
2. data collection, which consists of acquiring raw data and information from experts, existing applications, documentation, etc.,
3. data analysis, which consists of filtering, clarifying, abstracting, and organizing the raw data,
4. classification, which consists of generalizing the findings for maximum coverage and in specializing the findings to identify the specific parts of the problem that change with the various possible uses, and,
5. evaluation of the domain model, the critical step of validating the results of the domain analysis process.
Note that without domain analysis, a project can hope for very little more than about 20% reuse. Because up to 65% of an application can come from domain-specific software, high levels of reuse (as well as the corresponding benefits) depends on the planning, discipline, and investment that comes though this kind of formal reuse [Poulin97]. Organizations that desire to achieve high levels of reuse can choose from several existing, effective, and proven methods.
We have solved the
“Metrics” Problem
Advocates of any discipline eventually come to realize that their ability to sell their idea to management depends on the idea’s return on investment. Likewise, reuse practitioners have learned the mantra, “business decisions drive reuse!” Since the early days of reuse, we have seen articles on metrics and economic models, many of them designed for use with specific programming languages or for specific purposes. For example, we have seen models for predicting the cost of development with reuse and models for finding the critical number of reusers necessary to “break-even” on a reuse investment [Frakes96]. This metrics work has succeeded in that [Poulin97]:
·
we have defined what to count as reuse and how to count
it,
·
we have defined metrics for reuse and can recommend
these metrics for immediate use on projects and within organizations,
·
we know how to assess the financial benefits of reuse
both in the short and long term.
We have solved the
“Organization for Reuse” Problem
The management structure of an organization often determines the failure or success of a reuse program. Face it; different reporting hierarchies and geographic distance (even if just down the hall) preclude strong, collaborative relationships. Many recently published reports correlate reuse results to the various ways of organizing for reuse, to include: lone producers, nested producers, pooled producers, and team producers [Fafchamps94]. Hewlett-Packard Labs found that the team producers concept worked best; this model corresponds to the successful “Parts Center” approach advocated by IBM [Bauer93].
Based on these experiences, organizations should entrust the development and maintenance of shared software to a “Reuse Development Team” [Poulin97]. As shown in the figure, the Reuse Development Team fits into the management structure on the same level as any software development organization. However, the Project Manager always puts the Reuse Development Team into place well before any of the other organizations so that the reuse team can create a foundation of shared software before any other development begins.
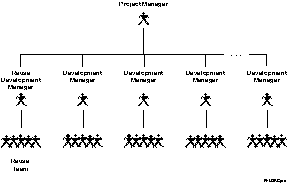
The budget for this reuse organization can come from contract investment funds, overhead funds, or a “tax” placed on each of the development managers. On one project, we funded the Reuse Development team with a 10% tax from each of our 7 development managers. In return, the development managers averaged 23% unmodified reuse from components supplied by the Reuse Development Team; a benefit of over twice their forced investment! Justification for such investments depends on the efficacious use of reuse metrics, as discussed above.
The Power of Reuse
Reuse allows us to efficiently build on previous work. It allows us to reduce duplication of effort. Just as proper research allows us to stand on the shoulders of others, software reuse allows us to extend ourselves with products provided for us. Rather than using valuable resources to re-write abstract data types and similar functions, we can plan ahead and design a domain-specific suite of software that will serve as the foundation for an entire product line of software applications.
We know that we have solved the issues above because we see reuse success stories all the time. Surely, many of the issues related to reuse, such as obtaining management commitment and funding, take a lot of effort to overcome. Considering the problems that we have solved, it amazes me that we keep seeing papers, for example, on reuse libraries. While reviewing papers over the years for journals such as IEEE Software and conferences such as the International Conference on Software Reuse (http://www.cs.vt.edu/icsr5), I have noticed that recent submissions address many of the same topics that have appeared many times in the past. Furthermore, they do not recognize previous work. These papers often present casual opinions, un-validated processes, or lack any scientific or engineering basis [Fenton94]. Those that proselytize reuse should apply the same logic to their research and not start from scratch. Reuse R&D needs to focus on the unsolved problems, such as interoperability, framework design, and component composition techniques.
Planning for reuse and investing in reusable software gives us the power to deliver more function, to deliver it faster, to deliver it with fewer defects, and to deliver it with less cost. Our experiences have solved many critical obstacles to reuse and led to many successful projects. By building on this work, I believe that the field of reuse will continue its tradition of progress and significantly contribute to our ability to meet our society’s voracious appetite for software.
References
[Arango93] Arango, Guillermo, “Domain Analysis Methods,” in Software Reusability. Wilhem Shaefer, Ruben Prieto-Diaz, and Masao Matsumoto, eds. Ellis Horwood, Chichester, U.K.,1993.
[Bauer93] Bauer, Dorothea, “A Reusable Parts Center,” IBM Systems Journal, Vol. 32, No. 4, 1993, pp. 620-624.
[Fafchamps94] Fafchamps, Danielle, “Organizational Factors and Reuse,” IEEE Software, Vol. 11, No. 5, September 1994, pp. 31-41.
[Fenton94] Fenton, Norman and Shari Lawrence Pfleeger, “Science and Substance: A Challenge to Software Engineers,” IEEE Software, Vol. 11, No. 4, July 1994, pp. 86-95.
[Frakes96] Frakes, Wiliam and Carol Terry, “Software Reuse: Metrics and Models,” ACM Computing Surveys, Vol. 28, No. 2, June 1996, pp. 415-435.
[Mili97] Mili, Hafedh, Estell Ah-Ki, Robert Godin, and Hamid Mcheick, “Another Nail to the Coffin of Faceted Controlled-Vocabulary Component Classification and Retrieval,” Proceedings of the 1997 ACM Symposium on Software Reusability (SSR’97), Boston, MA, 17-20 May 1997. Published in ACM Software Engineering Notes (SEN), Vol. 22, No. 3, May 1997, pp. 89-98.
[Poulin94] Poulin, Jeffrey S. and Keith W. Werkman, “Software Reuse Libraries with Mosaic,” 2nd International World Wide Web Conference: Mosaic and the Web, Chicago, Illinois, 17-20 October 1994. URL: http://www.ncsa.uiuc.edu/SDG/IT94/Proceedings/DDay/werkman/www94.html
[Poulin97] Poulin, Jeffrey S., Measuring Software Reuse: Principles, Practices, and Economic Models. Addison-Wesley (ISBN 0-201-63413-9), Reading, MA, 1997.
[Prieto-Diaz87] Prieto-Diaz, Ruben, and Peter Freeman, “Classifying Software for Reusability,” IEEE Software, Vol. 4, No. 1, January 1987, pp. 6-16.
[Yourdon96] Yourdon, Ed, “Lipstick on a Pig or a Real Silver Bullet?,” American Programmer, Vol. 9, No. 11, November 1996, pp. 25-29.